
We present Vera 1.5, a frontier-class large language model developed by Cortex Research, demonstrating competitive performance across multiple challenging benchmarks. Built on a high-sparsity Mixture of Experts (MoE) architecture with a 200,000-token context window, Vera 1.5 achieves exceptional results in agentic reasoning, competitive programming, and mathematical reasoning. The model was trained on 30 trillion tokens using NVIDIA B200 GPU infrastructure with FP8 precision, emphasising computational efficiency while maintaining state-of-the-art capabilities.
Introduction
Cortex Research focuses on creating cutting-edge frontier AI systems designed for positive global impact. Our work emphasises safe, scalable AI that solves humanity's toughest challenges, from healthcare breakthroughs to climate solutions. Vera 1.5 represents our commitment to advancing AI capabilities while maintaining accessibility and promoting responsible development practices within the broader AI research community.
The development of Vera 1.5 addresses critical challenges in modern AI systems: achieving frontier-level performance while optimising computational efficiency, extending context understanding to enable complex workflows, and demonstrating that independent research organisations can contribute meaningfully to advancing the state-of-the-art in artificial intelligence.
Vera 1.5 is built on a Mixture of Experts architecture with high sparsity configuration, featuring a 200,000-token context window, training on 30 trillion tokens from diverse data sources, FP8 precision training for enhanced computational efficiency, and a knowledge cutoff of January 1, 2025.
Model Architecture
Mixture of Experts
Vera 1.5 employs a Mixture of Experts (MoE) architecture, a design paradigm that offers significant advantages over traditional dense models. MoE models activate only a subset of parameters for each input token — specifically 30–40% during inference — dramatically reducing computational requirements while maintaining large total parameter counts. This efficiency stems from reduced arithmetic operations per token and architectural properties that favour parallelisation over serial computation.
Vera 1.5 implements a high sparsity configuration optimised for GPU utilisation. The sparse activation pattern allows the model to leverage massive parameter capacity while maintaining practical inference costs, ensuring favourable network communication patterns compared to dense architectures.
200K Context Window
Vera 1.5 features a 200,000-token context window, enabling the model to process and reason over extensive documents, entire codebases, and complex multi-turn conversations without segmentation. This enables comprehensive document analysis, sophisticated agentic workflows, large-scale codebase comprehension, and simultaneous processing of multiple academic papers for meta-analysis and hypothesis generation.
FP8 Precision Training
Vera 1.5 was trained entirely using FP8 (8-bit floating point) precision on NVIDIA B200 GPUs during Q4 2025. This delivers 30–50% faster training, up to 22% faster inference, a 14% lower memory footprint, and 19% higher throughput — with near-identical training loss curves compared to BF16 baselines and performance parity within 1–2 points on all reasoning benchmarks.
Benchmark Evaluation
We evaluate Vera 1.5 across six challenging benchmarks covering mathematical reasoning, scientific knowledge, software engineering, and agentic capabilities — representing the diverse skill domains essential for general-purpose AI systems.
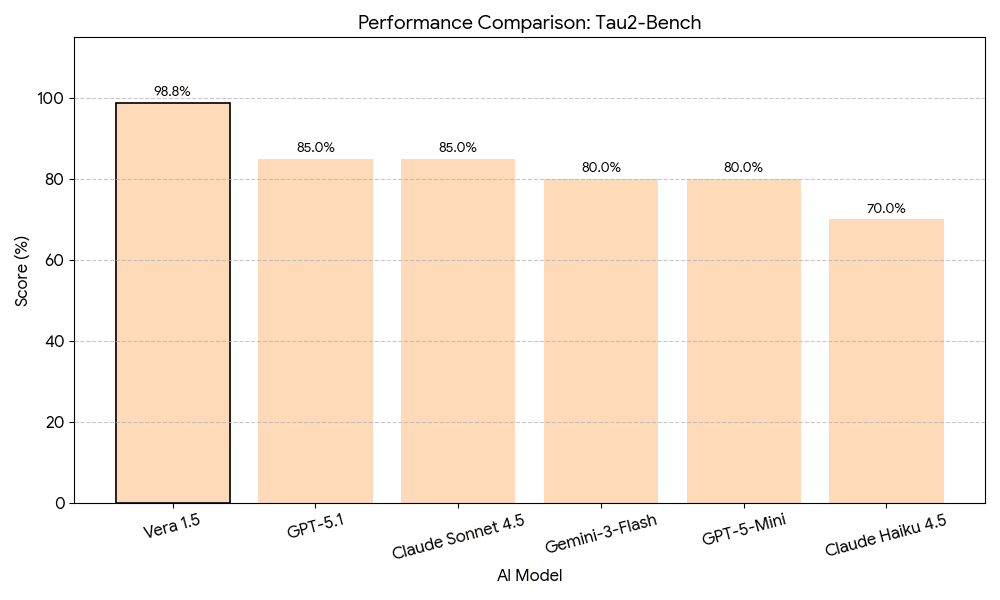
Agentic Reasoning — τ²-Bench
The τ²-Bench evaluates conversational agents in dual-control environments, assessing an agent's ability to understand user intent, execute control actions, and maintain coherent multi-turn interactions. Vera 1.5 achieves an exceptional 98.8% — the highest score among all evaluated models — demonstrating particular strength in agentic workflows, state management across extended interactions, and appropriate handling of ambiguous instructions.
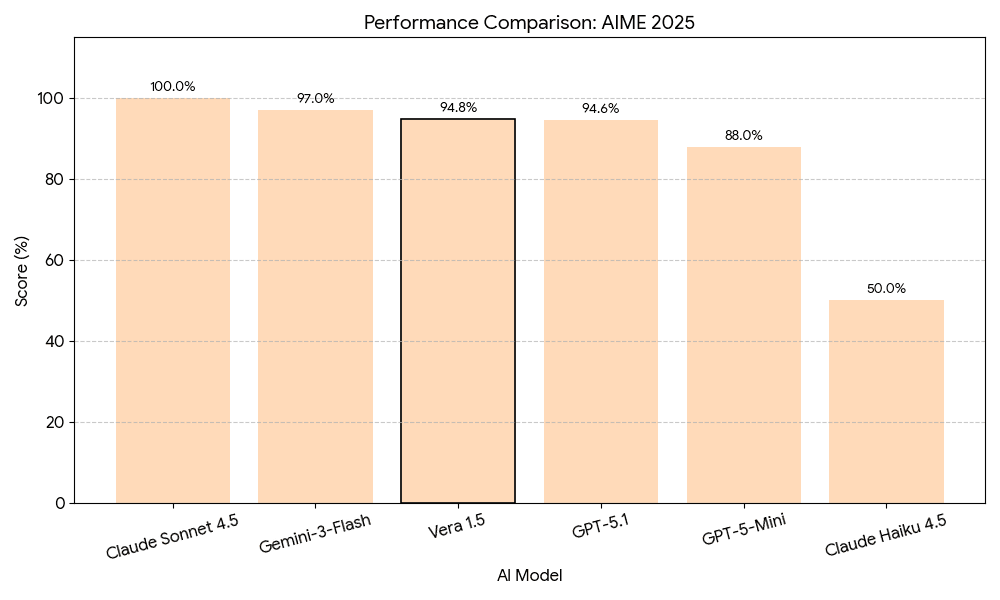
Mathematical Reasoning — AIME 2025
The American Invitational Mathematics Examination represents one of the most challenging mathematics competitions for high school students, requiring advanced problem-solving in algebra, geometry, number theory, and combinatorics. Vera 1.5 achieves 94.8%, reflecting the model's ability to formulate multi-step solution strategies and execute precise symbolic manipulation at olympiad level.
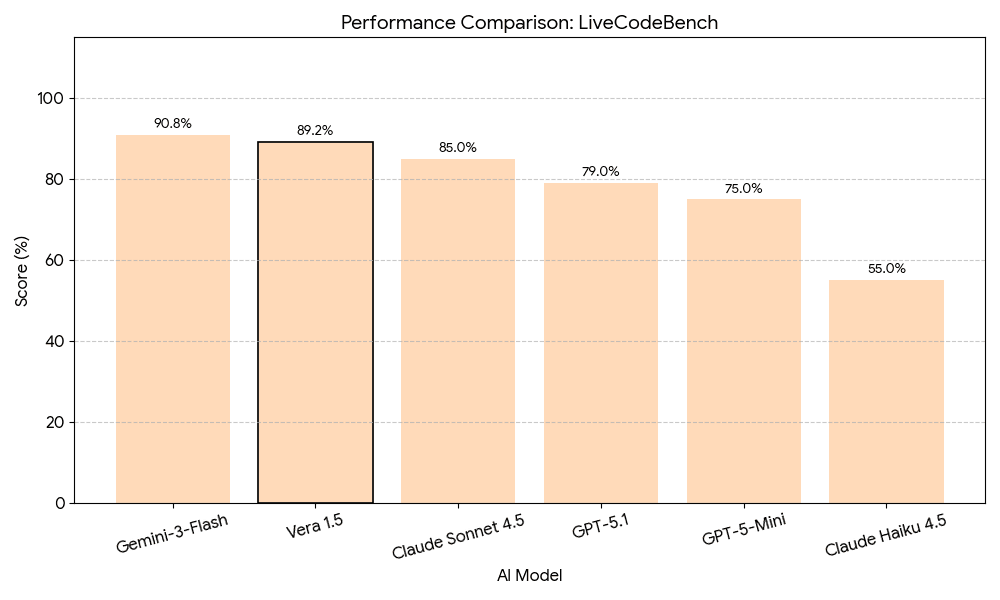
Competitive Programming — LiveCodeBench
LiveCodeBench continuously collects fresh programming problems from competitive coding platforms, ensuring evaluation on truly novel challenges without training data contamination. Vera 1.5 achieves 89.2%, demonstrating robust algorithmic thinking, efficient data structure use, edge-case handling, and code correctness under strict test evaluation.
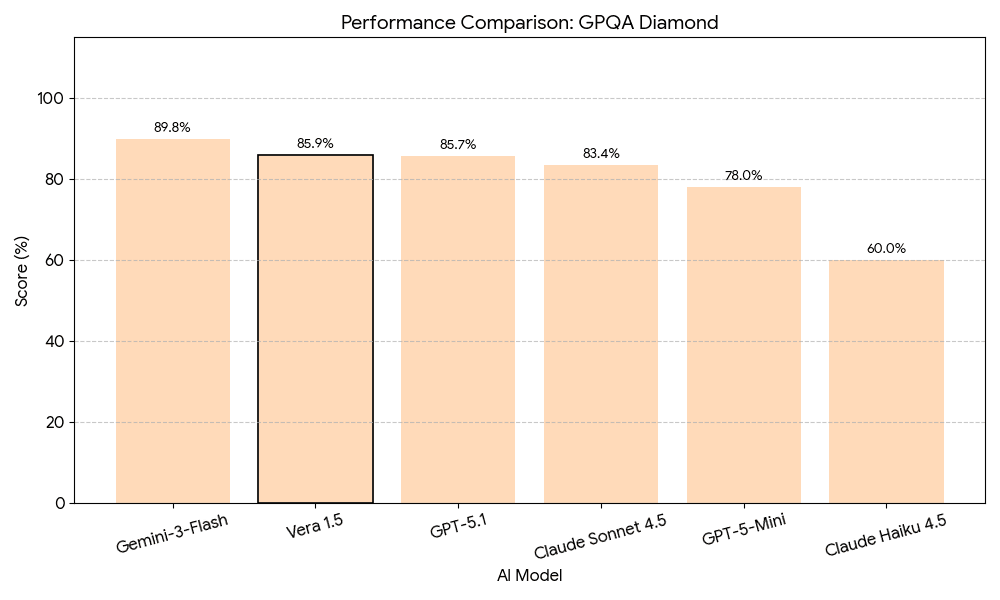
Scientific Knowledge — GPQA Diamond
The Graduate-Level Google-Proof Q&A Diamond benchmark tests PhD-level knowledge across biology, chemistry, and physics. Questions are carefully designed to be difficult for search engines, requiring deep domain expertise. Vera 1.5 scores 85.9%, demonstrating strong understanding of graduate-level scientific concepts and the ability to apply complex domain knowledge to novel problems.
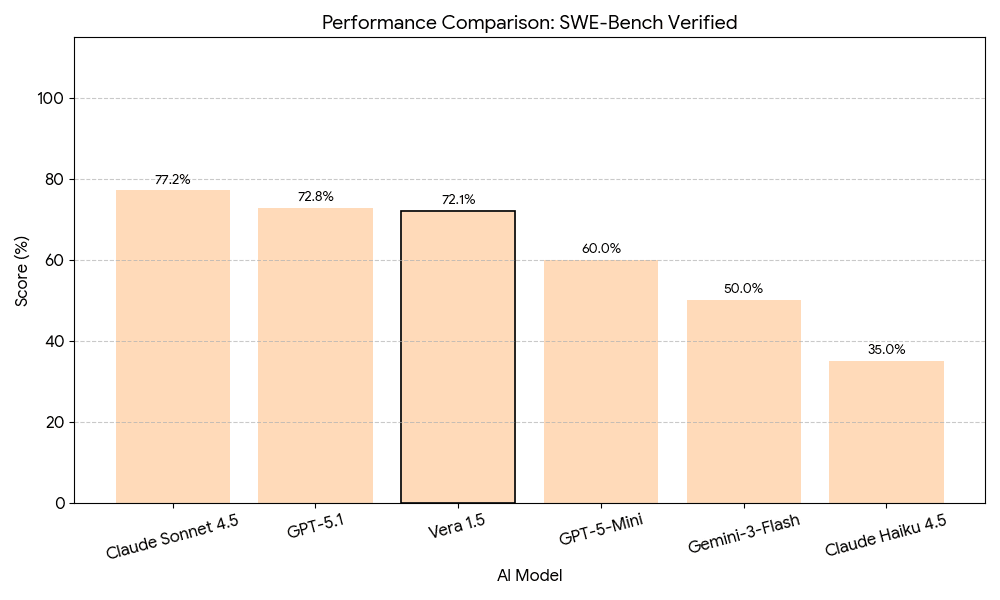
Software Engineering — SWE-Bench Verified
SWE-Bench Verified tests AI models on real-world software engineering tasks derived from GitHub issues and pull requests, requiring models to understand existing codebases, identify bugs, and implement correct solutions. Vera 1.5 scores 72.1%, demonstrating practical software engineering capability including bug diagnosis, root-cause identification, and navigating large multi-file codebases.
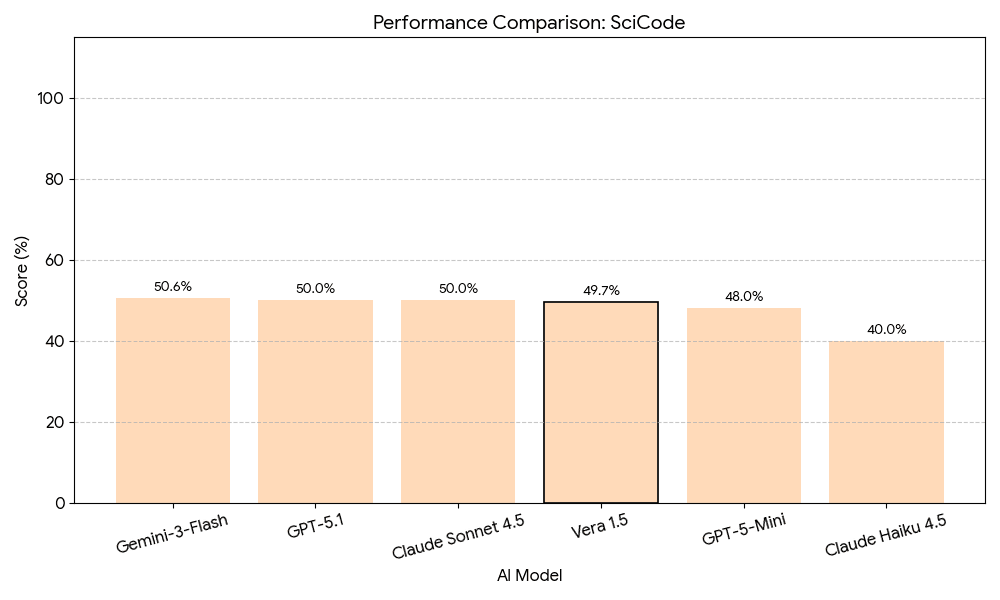
Scientific Computing — SciCode
SciCode evaluates models on research-level scientific computing tasks requiring implementation of algorithms from computational physics, chemistry, biology, and other scientific domains. Vera 1.5 scores 49.7%. This benchmark represents one of the most challenging evaluations, with all frontier models achieving scores near 50% — indicating that research-level scientific programming remains an open frontier challenge.
Comparative Analysis
| Benchmark | Score | Domain |
|---|---|---|
| τ²-Bench | 98.8% | Agentic Reasoning |
| AIME 2025 | 94.8% | Mathematical Reasoning |
| LiveCodeBench | 89.2% | Competitive Programming |
| GPQA Diamond | 85.9% | Scientific Knowledge |
| SWE-Bench Verified | 72.1% | Software Engineering |
| SciCode | 49.7% | Scientific Computing |
Vera 1.5's 98.8% score on τ²-Bench represents exceptional performance on conversational agent tasks, suggesting strength in multi-turn interactions and coherent state management across complex workflows. With 94.8% on AIME 2025, Vera 1.5 demonstrates advanced mathematical problem-solving at olympiad level, while the 89.2% on LiveCodeBench confirms strong algorithmic thinking on contamination-free problems.
The MoE architecture enables Vera 1.5 to achieve frontier-level performance while maintaining computational efficiency. Sparse activation reduces inference costs compared to dense models of equivalent capability, and combined with FP8 precision, Vera 1.5 offers strong performance-per-compute ratios across all evaluated domains.
Applications and Use Cases
Vera 1.5's exceptional τ²-Bench performance makes it well-suited for agentic workflows — customer service automation, technical support agents, personal assistants, and interactive tutoring systems that maintain coherent pedagogical context over long sessions. Strong performance on LiveCodeBench and SWE-Bench Verified enables practical software engineering applications including code generation, automated bug detection, and large-scale refactoring, with the 200K context window allowing Vera 1.5 to comprehend entire project structures.
PhD-level scientific knowledge demonstrated on GPQA Diamond supports literature review and synthesis, hypothesis generation from experimental data, and scientific computing assistance. The extended context window enables comprehensive document understanding for legal review, financial analysis, medical records, and research paper summarisation — all without information loss from segmentation.
Limitations and Future Work
The 49.7% SciCode score, while competitive with other frontier models, indicates substantial room for improvement in research-level computational tasks. Very long-context models may also experience "lost in the middle" effects where information positioned centrally receives less attention — applications requiring precise retrieval from arbitrary context positions may need additional optimisation. With training data ending January 1, 2025, applications requiring current information must implement retrieval-augmented generation or other knowledge-updating mechanisms.
Future research directions include enhanced scientific reasoning through specialised training curricula, multimodal capabilities extending Vera's architecture to process images and audio, improved inference efficiency through advanced quantisation and speculative decoding, and continued research into AI safety, robustness, and alignment with human values.
Conclusion
Vera 1.5 represents a significant achievement in UK frontier AI development by an independent research organisation. Through careful architectural choices — sparse MoE design, FP8 precision training, and an extended 200K context window — Vera 1.5 achieves competitive performance across diverse evaluation domains while maintaining computational efficiency.
The model's exceptional 98.8% score on τ²-Bench demonstrates particular strength in agentic reasoning and conversational interaction, a critical capability for practical AI deployment. Strong performance on mathematical reasoning, competitive programming, and scientific knowledge establishes Vera 1.5 as a well-rounded system suitable for diverse applications.
Cortex Research remains committed to developing AI systems that advance human flourishing while prioritising safety, scalability, and positive societal impact. Vera 1.5 represents an important step in this mission — demonstrating that cutting-edge capabilities can be built and remain accessible beyond a small number of well-resourced institutions.


